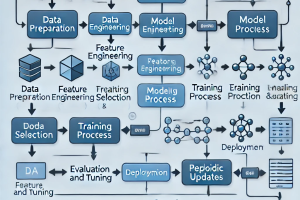
this is the visualization of the classifier-module
https://github.com/DuskoPre/AutoCoder/wiki/visualization-of-how-the-data-flows-through-the-%60CodeFormatterML%60-classifier-module
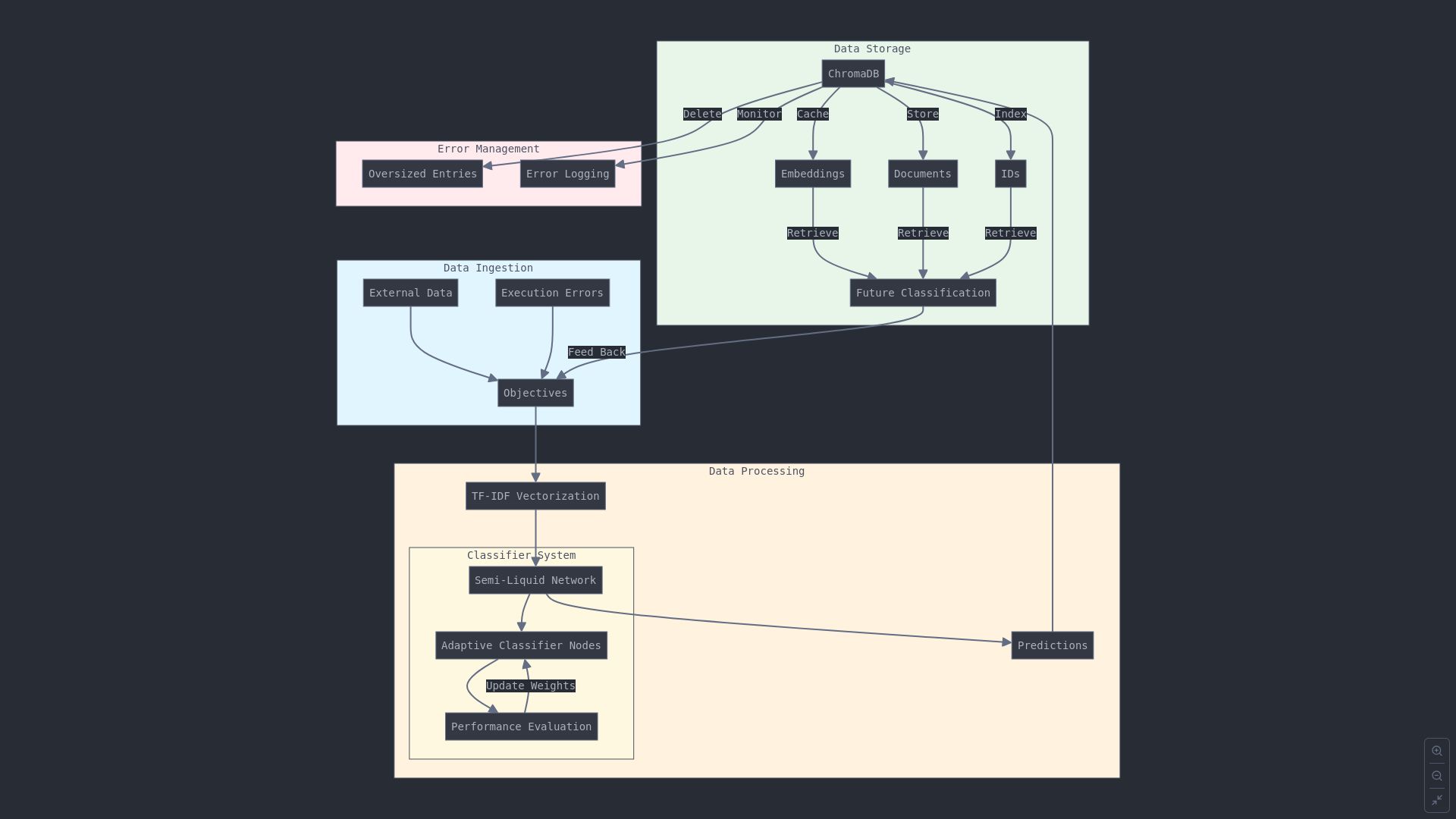
Creating a clear, step-by-step visualization of how the data flows through the CodeFormatterML classifier module, especially in an agent-based workflow similar to AutoGPT or BabyCoder, involves breaking down the process into manageable phases. The classifier here integrates multiple components, including data preparation, semi-liquid networks, ChromaDB for storage, and updates based on model performance.
Here’s a structured visualization of how data is processed in this workflow:
Visual Outline
-
Data Ingestion and Objective Setup
- Input Sources: The agent retrieves objectives from external sources or files (
objective3a.txt) or command-line arguments.
- Data Categorization: Objectives are categorized based on keywords (like "correction") and execution errors from ChromaDB.
- Training Data Creation: Objectives and errors are labeled and split into classes (
0 for correct, 1 for needing correction).
-
Vectorization and Initial Model Training
- Text Vectorization: The
TfidfVectorizer transforms text-based objectives and errors into numerical vectors.
- Training Initial Classifier: A
RandomForestClassifier is initialized and tuned using GridSearchCV. The model is trained on the transformed vectors.
-
Semi-Liquid Network Initialization
- Classifier Nodes: Each classifier is wrapped in an
AdaptiveClassifierNode, which tracks model importance and performance.
- Network Setup: These nodes are connected in a
SemiLiquidNetwork, allowing dynamic updates of each classifier based on performance metrics.
-
Prediction and Classification
- Content Classification: When new content is processed, the
semi_liquid_network makes predictions, where each classifier node’s predictions are weighted by importance.
- Caching: Classified content is stored in ChromaDB with metadata, including predicted class labels for future retrieval.
-
Model Updating and Performance Adjustment
- Performance Tracking: After each batch of predictions, the performance of classifiers is evaluated. The network adjusts each node's importance based on its recent performance.
- Continuous Learning: The main classifier and the
semi_liquid_network adaptively update, retraining with a mix of new and historical data.
-
Memory Management and Cleanup
- Garbage Collection: To prevent memory issues, garbage collection is triggered periodically.
- Error Handling: Oversized or problematic entries are removed from ChromaDB to optimize future retrieval.

in comparison to the AutoGPT classifier:
Summary Table
| Aspect |
AutoGPT (LLM-Based) |
AutoML (Data-Driven) |
| Training Requirement |
None |
Yes, uses labeled data |
| Real-Time Adaptation |
Yes, via prompt adjustments |
Yes, through retraining |
| Ideal for |
Fast sentiment analysis |
Long-term classification with updates |
This comparison highlights AutoGPT’s flexibility and ease versus AutoML's structured, adaptable approach for accuracy-driven tasks.
Comparison to AutoGPT Workflow
AutoGPT (LLM-Based):
- Focus on Prompt and Real-Time Interpretation: Uses a prompt-based agent to classify based on the LLM’s internal knowledge without formal training or retraining.
- Feedback Loop: Can refine classification based on iterative prompts but does not learn from new data.
AutoML (Data-Driven):
- Focus on Structured, Data-Driven Learning: Trains on a large dataset, selecting and tuning models based on performance metrics.
- Adaptable Over Time: Continuously retrains to integrate new data and improve accuracy with each update

-
Classifier System Enhancements:
- Input Layer: Add an "Input Layer" node before the "TF-IDF Vectorization" to mark the start of data processing.
- Embedding Layer: Introduce an "Embedding Layer" between the "TF-IDF Vectorization" and "Classifier System" for deeper representation learning.
- Dense Layer: Include a "Dense Layer" within the "Classifier System," indicating intermediate processing within the model.
- Output Layer: Add an "Output Layer" node to show the final stage of classification before predictions are generated.
-
Enhanced Adaptive Mechanism:
- Activation Function: Within the "Adaptive Classifier Nodes," integrate a node labeled "Activation Function" to reflect its role in determining the nodes' response.
- Optimization: Introduce an "Optimization" process alongside "Update Weights" to reflect the full training loop.
-
Expanded Error Management:
- Add nodes like "Error Correction" and "Outlier Detection" within the "Error Management" section, connected to "Oversized Entries" and "Error Logging," enhancing the error-handling loop.
-
New Relationships:
- Ensure that all layers (Input, Embedding, Dense, and Output) are connected sequentially within the flow of the "Classifier System."
- Link "Optimization" to both "Update Weights" and "Performance Evaluation" for a feedback mechanism that helps improve classification accuracy.